WineQuality.r
Data Source archive.ics.uci.edu
# Descision Tree
wine <- read.csv('winequality-white.csv', sep=';', header = TRUE)
wine <- rbind(wine, read.csv('winequality-red.csv', sep=';', header = TRUE))
hist(wine$quality)
# The wine quality values appear to follow a fairly normal,
#bell-shaped distribution, centered around a value of six.
Histogram 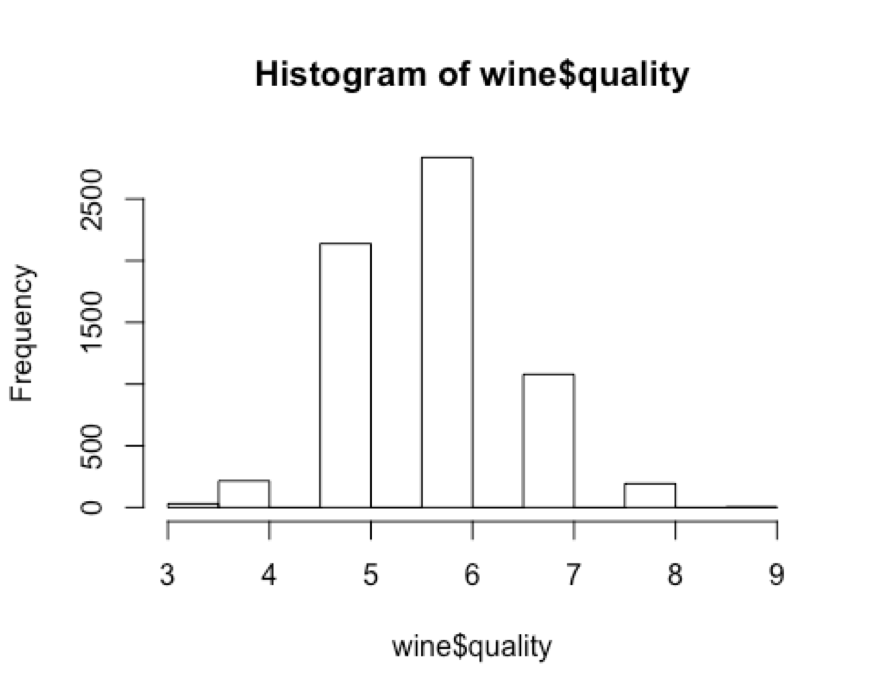
summary(wine)
#partition the data
wine_train <- wine[1:3248, ]
wine_test <- wine[3249:6497, ]
m.rpart <- rpart::rpart(quality ~ ., data = wine_train)
m.rpart
summary(m.rpart)
## Call:
## rpart::rpart(formula = quality ~ ., data = wine_train)
## n= 3248
##
## CP nsplit rel error xerror xstd
## 1 0.17309330 0 1.0000000 1.0009756 0.02583728
## 2 0.04673914 1 0.8269067 0.8284360 0.02410107
## 3 0.03098582 2 0.7801676 0.7908229 0.02375595
## 4 0.01380180 3 0.7491817 0.7603411 0.02229241
## 5 0.01113703 4 0.7353799 0.7515058 0.02204882
## 6 0.01000000 5 0.7242429 0.7434067 0.02183699
##
## Variable importance
## alcohol density volatile.acidity
## 39 22 13
## chlorides free.sulfur.dioxide total.sulfur.dioxide
## 11 6 5
## citric.acid pH sulphates
## 1 1 1
## fixed.acidity
## 1
##
```r
library(rpart.plot)
## Loading required package: rpart
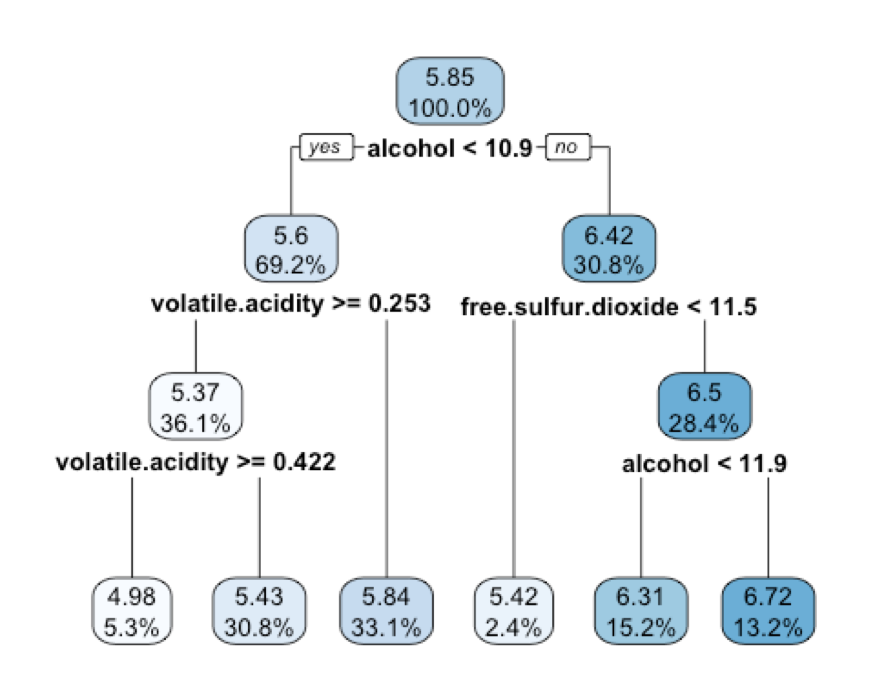
rpart.plot(m.rpart, digits = 3)
Decision Tree
Because alcohol was used first in the tree, it is the single most important predictor of wine quality.